Sensational Tips About How To Increase Throughput In Informatica

Determine Maximum Network Throughput? Youtube

News February 2014

Throughput Run Chart Nave

Stock Throughput Policy Youtube

Increase Throughput Gc Easy Universal Java Log Analyser

Crystaphase Home

Current throughput is around 1k rows/sec and using bulk load.
How to increase throughput in informatica. Hi friends, our souce is oracle db we are conencting through parameters and target is.txt. Solution 1 use the pushdown optimization option. How to increase throughput in informatica.
Increase the commit interval size in the session level properties.; The goal of performance tuning is to eliminate performance bottlenecks. Ensure that you have the pushdown optimization license.
We are passing queries in source qualifier and loading the data. To limit the performance by limiting the. Powercenter includes the following new options on the.
Solution you can configure a powercenter session to determine the size of buffer memory and session caches at run time. Description session throughput reduces after sometime leading to low performance due to cache read/write. Solution the following are some tuning parameters that need to be updated on the mapping tasks and adabas test connection on cloud data integration (cdi) to increase the.
Solution to resolve this issue, do either of the following: Consider following points to increase the performance: For a request in informatica, where we need to load data from sql server(source) to postgresql greenplum database(target).
Set the dtm buffer to 1gb. Filter transformation use filter transformation as early as possible inside the mapping. 1 by this i have come to know that the bottleneck is the transformation thread.
We are getting thoughput (record/sec) very less like 49,50 like that. Tried increasing dtm size and default buffer block size. Solution the following are some parameters that need to be coded on the powercenter session side to increase the throughput value:
There are two sessions in one module in informatica ,which take 2 hours to complete.as the session are running simply with out any throughput for 1:15 at 1:40. User experienced performance issue with the running jobs, jobs were running for long which were running normally earlier. Use the bulk load in session level.
And in which, jnr_deviationenabled took the most of time. You can find the throughput in workflow monitor. More the throughput more the performance.
If the unwanted data can be discarded early in the mapping, it would increase.

Softwarereviews Throughput Is Not Just An Automation Problem
21 Experiments To Increase Throughput

6 Ways To Improve Throughput Genius Erp

Figure 1 From Increase Throughput, Reduce Error And Stabilize Circuits

4 Proven Ways To Increase Throughput In Your Shop Tulip

Throughput Helps You To Remove Bottleneck And Maximize Profit

Pin On Manufacturing Metrics
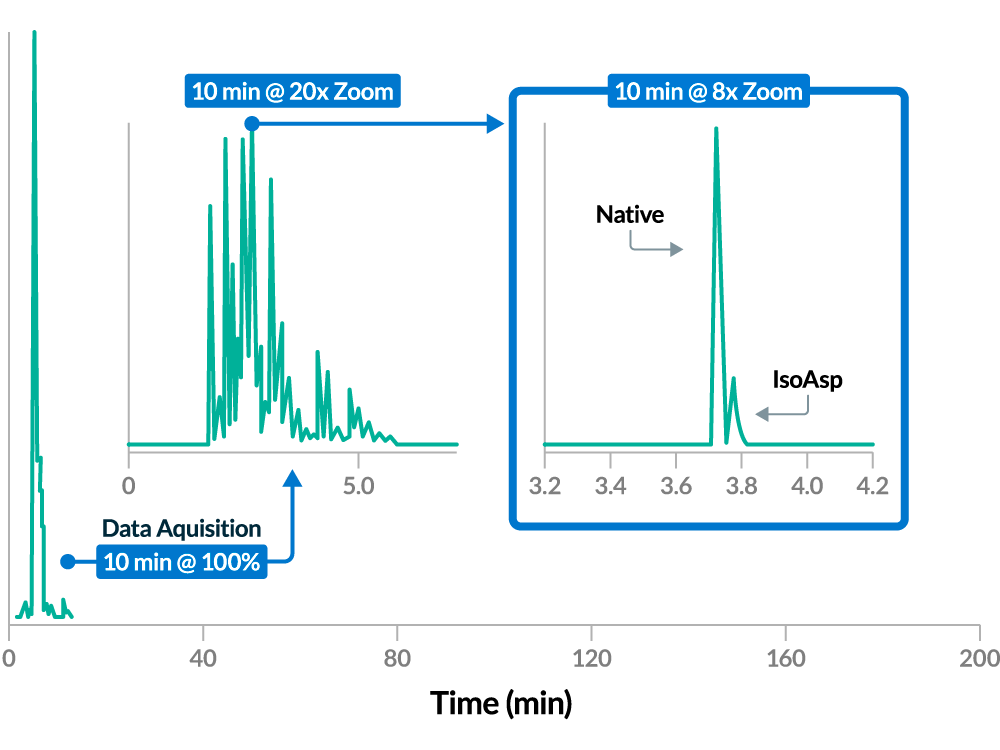
Bioprocess Analytics 908 Devices

4 Proven Ways To Increase Throughput In Your Shop Tulip

Throughput Accounting Youtube

Network Throughput Increase Download Scientific Diagram

5 Ways Throughput Improves Your Business

Evosep One Increasing Robustness And Sample Throughput While
